Lecture 12a The Boltzmann Machine learning algorithm
The goal of learning
- • We want to maximize the product of the probabilities that the Boltzmann machine assigns to the binary vectors in the training set.
- – This is equivalent to maximizing the sum of the log probabilities that the Boltzmann machine assigns to the training vectors.
- • It is also equivalent to maximizing the probability that we would obtain exactly the N training cases if we did the following
- – Let the network settle to its stationary distribution N different times with no external input.
- – Sample the visible vector once each time.
- • 볼츠만 머신이 트레이닝 세트의 바이너리 벡터에 할당할 확률의 곱을 최대화하려고 합니다.
- 이것은 볼츠만 머신이 트레이닝 벡터에 할당하는 로그 확률의 합을 최대화하는 것과 같습니다.
- • 또한 다음과 같은 경우 N 개의 교육 사례를 정확하게 얻을 수 있는 확률을 극대화하는 것과 같습니다.
- 외부 입력없이 N 회에 걸쳐 네트워크를 고정 분배로 정착시킵니다.
- 매번 한 번씩 visible 벡터를 샘플링하십시오.
Why the learning could be difficult (이해 잘 못함...)

A very surprising fact
Everything that one weight needs to know about the other weights and the data is contained in the difference of two correlations.
한 가중치가 다른 가중치와 데이터에 대해 알아야 할 모든 것은 두 상관 관계의 차이에 포함됩니다.

 Why is the derivative so simple?
Why is the derivative so simple?
- • The probability of a global configuration at thermal equilibrium is an exponential function of its energy.
- – So settling to equilibrium makes the log probability a linear function of the energy.
- • 열 평형 상태에서 global configuration의 확률은 에너지의 지수 함수이다.
- 따라서 평형에 도달하면 로그 확률이 에너지의 선형함수가됩니다.
• The energy is a linear function of the weights and states, so:
• 에너지는 가중치와 상태의 선형 함수이므로 다음과 같습니다.
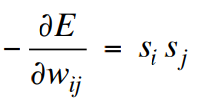
- • The process of settling to thermal equilibrium propagates information about the weights.
- – We don’t need backprop.
- • 열 평형 상태로 정착하는 과정은 가중치에 대한 정보를 전달합니다.
- 우리는 역방울이 필요 없어.
Why do we need the negative phase?
The positive phase finds hidden configurations that work well with v and lowers their energies.
The negative phase finds the joint configurations that are the best competitors and raises their energies.
긍정적인 단계는 v와 잘 작동하는 hidden configurations을 찾아 에너지를 낮춥니다.
부정적인 단계는 최고의 경쟁자이며 에너지를 높이는 joint configurations 을 찾습니다.

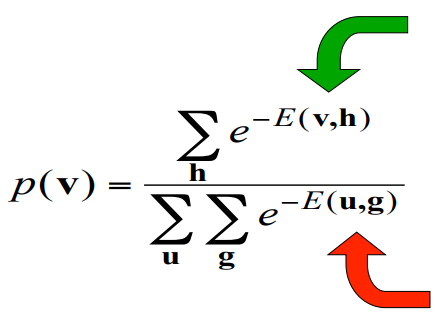
초록 화살표가 positive, 빨간화살표가 negative
An inefficient way to collect the statistics required for learning
Hinton and Sejnowski (1983)
- • Positive phase: Clamp a data vector on the visible units and set the hidden units to random binary states.
- – Update the hidden units one at a time until the network reaches thermal equilibrium at a temperature of 1.
- – Sample <Si,Sj> for every connected pair of units.
- – Repeat for all data vectors in the training set and average.
- • Negative phase: Set all the units to random binary states.
- – Update all the units one at a time until the network reaches thermal equilibrium at a temperature of 1.
- – Sample <Si,Sj> for every connected pair of units.
- – Repeat many times (how many?) and average to get good estimates.
- • Positive phase : 보이는 단위에 데이터 벡터를 클램프하고 숨겨진 단위를 임의의 이진 상태로 설정합니다.
- 네트워크가 1의 온도에서 열 평형에 도달 할 때까지 숨겨진 유닛을 한 번에 하나씩 업데이트하십시오.
- 연결된 모든 쌍의 샘플<Si,Sj> .
- 훈련 세트의 모든 데이터 벡터와 평균에 대해 반복합니다.
- • Negative phase : 모든 단위를 임의의 이진 상태로 설정합니다.
- 네트워크가 온도 1에서 열 평형에 도달 할 때까지 한 번에 하나씩 모든 장치를 업데이트하십시오.
- 연결된 모든 쌍의 샘플<Si,Sj> .
- 여러 번 반복 (몇 번이나 되풀이)하고 좋은 추정을 위해 평균을 낸다.