Lecture 12c Restricted Boltzmann Machines
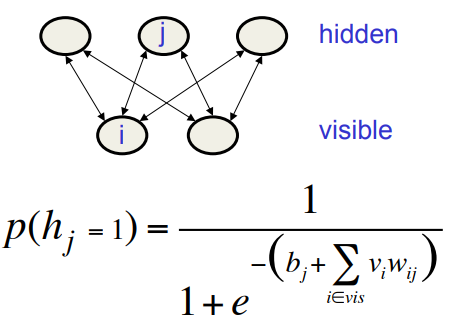
Restricted Boltzmann Machines
- • We restrict the connectivity to make inference and learning easier.
- – Only one layer of hidden units.
- – No connections between hidden units.
- • In an RBM it only takes one step to reach thermal equilibrium when the visible units are clamped.
- – So we can quickly get the exact value of :
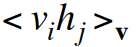
- – So we can quickly get the exact value of :
- • 우리는 추론과 학습을 쉽게하기 위해 연결성을 제한합니다.
- 숨겨진 유닛 한 레이어.
- 숨겨진 유닛간에 연결이 없습니다.
- • RBM에서는 보이는 단위가 클램프되었을 때 열 평형에 도달하는 데 한 걸음 만 걸립니다.
- 그래서 우리는 다음의 정확한 값을 빨리 얻을 수 있습니다: <vihj>v
PCD: An efficient mini-batch learning procedure for Restricted Boltzmann Machines (Tieleman, 2008)
- • Positive phase: Clamp a datavector on the visible units.
- – Compute the exact value of
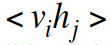 for all pairs of a visible and a hidden unit.
for all pairs of a visible and a hidden unit. - – For every connected pair of units, average over all data in the mini-batch.
- – Compute the exact value of
- • Negative phase: Keep a set of “fantasy particles”. Each particle has a value that is a global configuration.
- – Update each fantasy particle a few times using alternating parallel updates.
- – For every connected pair of units, average over all the fantasy particles.
A picture of an inefficient version of the Boltzmann machine learning algorithm for an RBM
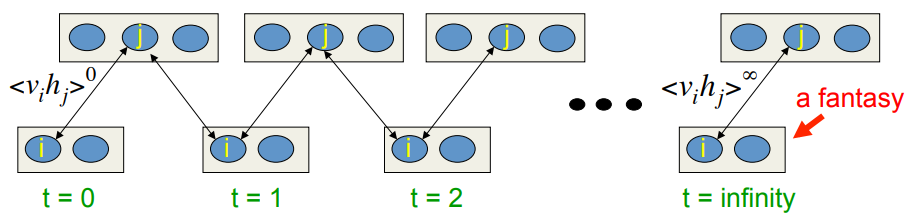
Start with a training vector on the visible units.
Then alternate between updating all the hidden units in parallel and updating all the visible units in parallel.
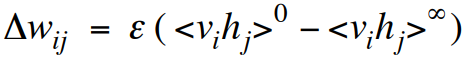
Contrastive divergence: A very surprising short-cut
Start with a training vector on the visible units.
Update all the hidden units in parallel.
Update the all the visible units in parallel to get a “reconstruction”.
Update the hidden units again.
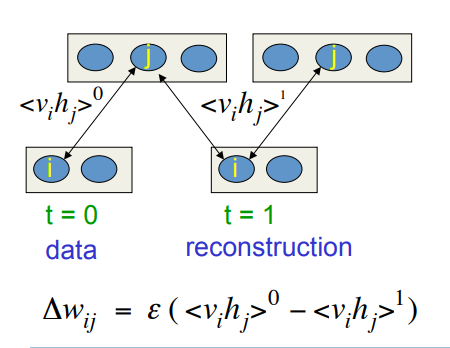
This is not following the gradient of the log likelihood. But it works well.
Why does the shortcut work?
- • If we start at the data, the Markov chain wanders away from the data and towards things that it likes more.
- – We can see what direction it is wandering in after only a few steps.
- – When we know the weights are bad, it is a waste of time to let it go all the way to equilibrium.
- • All we need to do is lower the probability of the confabulations it produces after one full step and raise the probability of the data.
- – Then it will stop wandering away.
- – The learning cancels out once the confabulations and the data have the same distribution.
- •우리가 데이터에서 시작한다면, 마르코프 사슬은 데이터에서 멀어지고 더 좋아하는 사물로 향합니다.
- 몇 단계 만에 방황하는 방향을 알 수 있습니다.
- 우리가 가중치가 나쁘다는 것을 알게되면 평형에 도달하게하는 것은 시간 낭비입니다.
- • 우리가해야 할 일은 하나의 단계를 거친 후 만들어지는 협업의 가능성을 낮추고 데이터의 확률을 높이는 것입니다.
- 그러면 방황하는 걸 멈출거야.
- confabulations와 데이터가 같은 배포를하면 학습이 취소됩니다.
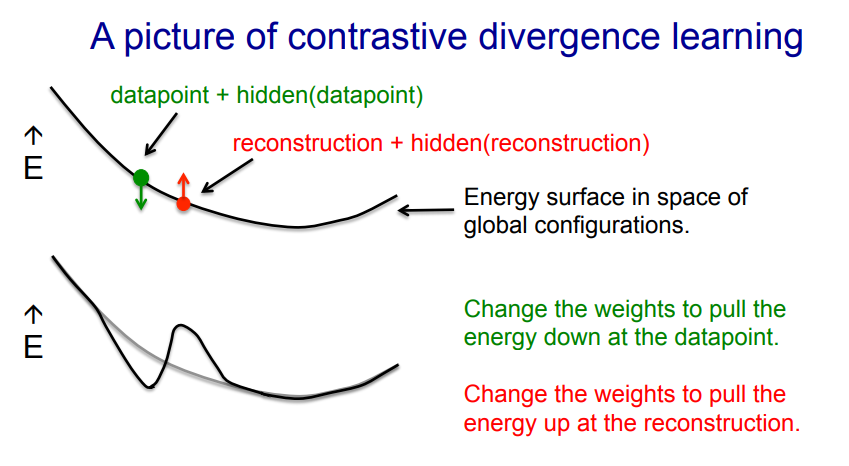 When does the shortcut fail?
When does the shortcut fail?
- • We need to worry about regions of the data-space that the model likes but which are very far from any data.
- – These low energy holes cause the normalization term to be big and we cannot sense them if we use the shortcut.
- – Persistent particles would eventually fall into a hole, cause it to fill up then move on to another hole.
- • A good compromise between speed and correctness is to start with small weights and use CD1 (i.e. use one full step to get the “negative data”).
- – Once the weights grow, the Markov chain mixes more slowly so we use CD3.
- – Once the weights have grown more we use CD10.
- •
우리는 모델이 좋아하지만 데이터로부터 아주 멀리 떨어져있는 데이터 공간의 영역에 대해 걱정할 필요가 있습니다.
- 이러한 저에너지 홀은 정규화 용어를 크게 만들며, 우리가 바로 가기를 사용한다면 그것을 감지 할 수 없습니다.
- 영구적 인 입자가 결국 구멍 속으로 들어가서 채워져 다른 구멍으로 이동합니다.
- • 속도와 정확성 사이의 좋은 절충안은 작은 가중치로 시작하여 CD1을 사용하는 것입니다 (즉, 하나의 전체 단계를 사용하여 "음수 데이터"를 얻는 것).
- 일단 가중치가 증가하면 마르코프 체인이 더 느리게 혼합되어 CD3을 사용합니다.
- 일단 가중치가 커지면 CD10을 사용합니다.